

Web indexing is the way search engines collect and store data from websites to answer search queries quickly. This system works through automated web crawlers that visit websites, scan pages, and build a searchable content index. It helps users find what they need without delays.
In simple terms, web indexing means creating a record of online pages so they can be found through search. It supports information retrieval by keeping track of what each page contains. On some websites, site-wide index pages or A–Z lists also help users browse content directly. Whether for a full search engine or just one site, indexing plays a key role in how we explore the web.
What is web indexing and how does it work?
Web indexing makes online pages easy to find without searching them one by one. It builds a searchable structure where content is stored and recalled quickly when a query is made. Without this system, finding results would take too long.
Search engines use a full-text indexing method, where every word on a page is scanned and added to a search index. This works faster than checking each web page during every search. The index acts like a map, pointing to where keywords or topics appear across the internet.
In the early days, web indexing followed models from book indexes, which listed terms along with page numbers. Some websites still use A–Z index pages, managed by people, to help users browse their content directly. But due to the size of the internet, search engines rely on automated indexing to handle the massive number of pages online.
Modern systems do more than just scan text. They also store metadata like page titles, languages, short descriptions, and even the page’s link connections. These extra signals help the engine decide which page is more useful. Indexes now also include images, videos, PDFs, and other file types. Text data like captions or file labels are extracted so that even non-text content can show up in search.
With more online content, from blogs to journals, web indexing has become essential for accessing reliable information across different fields.
How did web indexing start and change over time?
Web indexing changed how we find information online. From simple lists to massive, automated search systems, it grew with the internet itself. This section explains how it started, scaled, and evolved into what we use today.
Manual beginnings and early tools
In the early 1990s, web directories helped users find websites. These were lists made by people, grouped by topic. But with more websites coming up, manual work became too slow.
In 1993, a tool called ALIWEB let site owners submit their pages with keywords and short descriptions. This system did not use a web crawler, so it relied fully on manual entries. ALIWEB stayed small, but it was an important early step.
A big shift came in 1994 when WebCrawler launched. It could index full text, meaning it scanned every word on a web page. That made the search much faster and more accurate.
Soon after, Lycos also began full-text scanning. It was developed at Carnegie Mellon and quickly built a large index. These tools set the base for modern search engine development.
Expansion through automation
In December 1995, AltaVista took indexing to a new level. It launched a full web crawl and index that covered 16 million documents. This was almost every page online at that time.
More engines followed. Excite, Infoseek, and Yahoo moved beyond directories to focus on search. Their indexes kept growing, and the need to rank results became urgent.
Then in 1998, Google arrived with PageRank. This system used the link structure of web pages to rank them by importance. Google’s fresh approach helped it scale fast. By 2000, it had the largest and most updated search index.
As of 2020, Google indexed over 400 billion documents, giving access to a huge part of the public internet.
New types of content and indexing methods
With time, search engines expanded beyond plain HTML pages. They added support for dynamic content, multimedia, and real-time updates. This led to specialized indexing for things like:
- Images
- Videos
- News
- Legal documents
- Patents
- Government records
Each of these needed custom indexing rules to match their format and content type.
Academic and domain-specific indexing
In 1997, CiteSeer was developed to index academic research papers, especially in computer science. It introduced autonomous citation indexing, where the system read documents, extracted citations, and linked papers together automatically.
CiteSeer went public in 1998 and later became CiteSeerX. This tool inspired Google Scholar and helped scholars search by paper title or citation. By the 2010s, CiteSeerX had indexed over 6 million research papers.
Today, many specialized search engines use web indexing to serve different communities and content types. They continue to grow with the internet, adapting to new needs and formats.
How do search engines index websites?
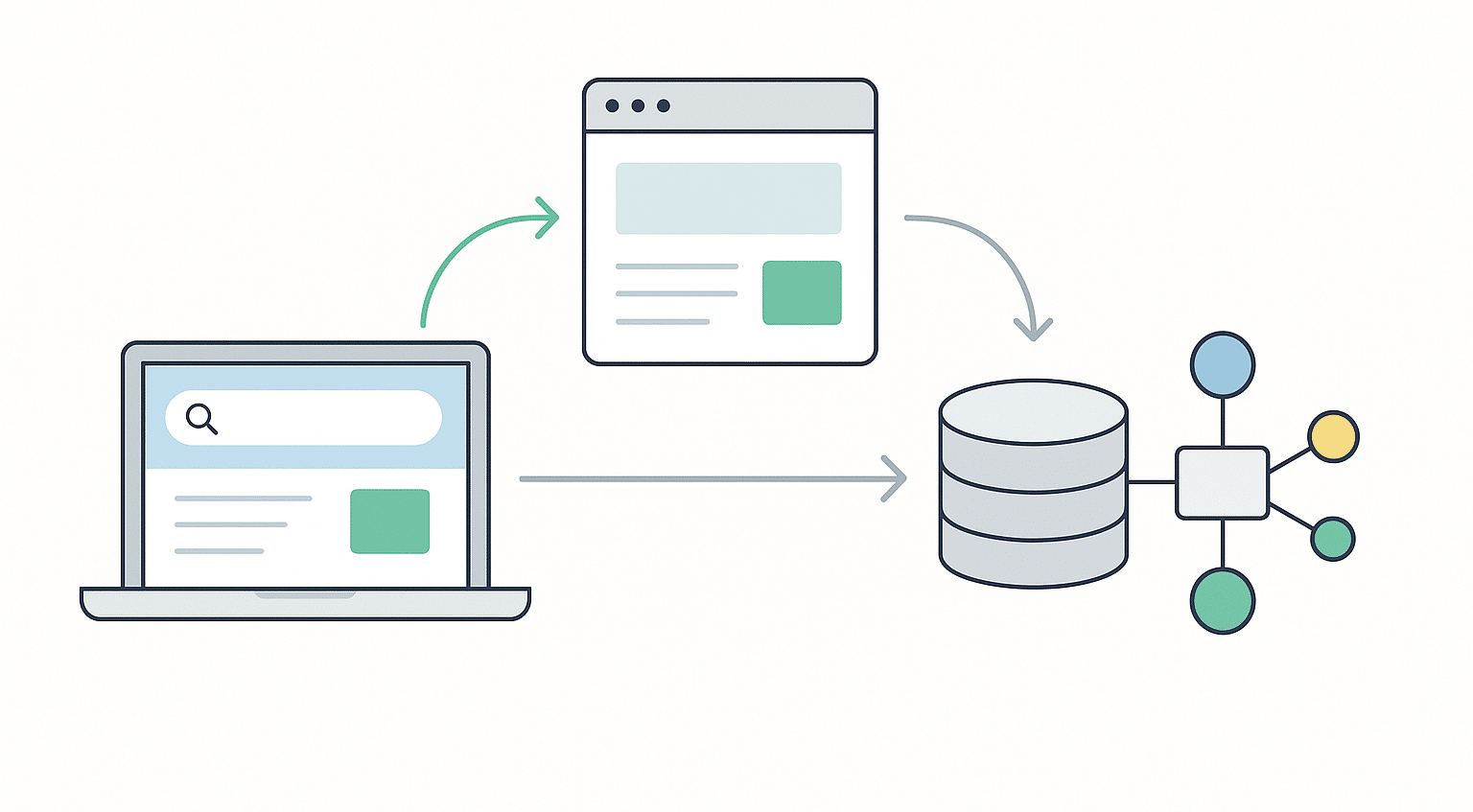
Web indexing runs through multiple steps, starting from crawling and ending with a structured search index. This section explains how pages are collected, processed, and made searchable.
Crawling and access control
Web crawlers are automated programs that visit websites and move through links. They fetch content and pass it to the indexing pipeline. Crawlers decide what to visit based on a page’s importance and how often it changes.
To manage the load, search engines use crawl scheduling systems. These systems help balance fresh content with computing costs. Crawlers also check the robots.txt file, which tells them which parts of a site to avoid. This rule is based on the Robots Exclusion Protocol, introduced in 1994.
Parsing content and building indexes
Once a page is collected, the system parses its content to pull out:
- visible text
- hyperlinks
- metadata like page titles and descriptions
The most important part of the system is the inverted index. This is a structure where every unique word is matched to all the pages that contain it. Instead of storing what is in each page, it stores where each word shows up.
This inverted index makes searches much faster. For example, a term like indexing will point to every document where that word appears, along with position details. Search engines can then quickly return matching pages.
Supporting data and performance tuning
The indexing system also stores details like anchor text, incoming links, and meta tags. These extra layers improve result quality. Earlier, engines used meta keywords, but those were misused, so full content is now the main source for indexing.
To handle the web’s size, engines compress data and distribute the index across many servers. These improvements help search results stay fast and relevant even with billions of pages.
Handling different content formats
Modern indexing is not limited to simple text. Search engines also process:
- PDFs, extracting readable text
- Images with text, using OCR
- Stored pages, kept in a page repository
During this stage, engines also measure signals like PageRank, page freshness, and content quality. Some indexes update in near real-time, especially for breaking news or trending topics.
What is the difference between commercial and academic web indexing?
Commercial web indexing
Commercial search engines like Google and Bing build extremely large search indexes designed for speed and general use. They focus on indexing pages that are popular, frequently updated, and likely to match common user queries.
These systems filter billions of URLs and store only the most useful content. To handle size, they split their index across global data centers, use partial indexing to save space, and refresh popular pages more often.
Their main goal is to deliver fast and relevant results to everyday users, across text, images, videos, and other media.
Academic indexing systems
Academic indexing focuses on narrow topics with deep detail. Tools like CiteSeer or Google Scholar index research papers, not general websites. They collect structured data like citations, authors, and paper titles.
Since many academic papers are locked behind paywalls, these engines mostly include open-access documents. Their index is smaller but more curated. They do not aim for full coverage of the internet, but rather accurate retrieval within scholarly content.
Indexes like PubMed and IEEE Xplore use similar technology but work only within specific academic fields.
Commercial Web Indexing vs Academic Indexing
| S.No | Commercial Web Indexing | Academic Indexing |
| 1 | Indexes the public web for general user queries | Indexes academic papers for research and education |
| 2 | Focuses on popular, fresh, and high-traffic pages | Focuses on scholarly relevance and citation value |
| 3 | Uses massive distributed data centers | Uses smaller, focused infrastructures |
| 4 | Partial indexing to handle duplicate or large pages | Full indexing of academic content where accessible |
| 5 | Handles multiple content types: text, images, videos | Primarily handles research papers and metadata |
| 6 | Prioritizes speed and search performance at scale | Prioritizes accuracy and academic credibility |
| 7 | Excludes pages using robots.txt or spam filters | Excludes paywalled content unless self-archived |
| 8 | Relies on link analysis like PageRank | Relies on citations and author metadata |
| 9 | Re-indexes popular pages frequently | Updates depend on access to new open-access documents |
| 10 | Examples: Google, Bing, Baidu | Examples: CiteSeer, Google Scholar, PubMed, IEEE Xplore |
Web indexing and its role in SEO
To show up in search results, a web page must first be indexed. In search engine optimization (SEO), getting content into a search index is the first step before ranking or visibility can happen.
Why indexing matters in SEO
If a page is not in the search index, it cannot appear for any user query. In SEO terms, web indexing means the search engine has added the page to its internal list of known URLs. That inclusion is what makes ranking possible.
SEO teams use several methods to help crawlers reach their content. One way is to submit an XML sitemap, which gives search engines a complete list of main URLs. Another method is improving the internal link structure so no important page gets left out. Pages that are not linked from anywhere, known as orphan pages, are often skipped during crawling.
Common problems that block indexing
Technical SEO audits often focus on why pages fail to be indexed. Slow-loading pages, duplicate content, and broken links are common reasons. A slow page can cause a crawler to drop off before saving the content. Even large websites face these gaps. In 2023, a study found that about 16 percent of important pages on big sites were missing from Google’s index.
Search engines may also reject pages that seem spammy or offer no value. Pages with copied content or overloaded keywords can be crawled but ignored. To avoid this, SEO best practices call for original and valuable content that provides clear user benefit.
Controlling what gets indexed
Some sites face the opposite issue, where too many low-value pages appear in search. This is called index bloat. It often happens with thin content, login pages, or search result pages. Webmasters manage this using the noindex tag, placed in the HTML meta section or set through HTTP headers.
When crawlers detect the noindex directive, they usually remove the page from future searches. Although search engines are not forced to obey, most major platforms follow it as a courtesy to site owners.
Good SEO practices support better indexing. These include keeping pages unblocked in robots.txt, submitting clean sitemaps, and making sure every page loads quickly and links properly. The link between indexing and SEO is strong. Without indexing, SEO has no base to build on.
Legal and ethical rules in web indexing

Web indexing plays a vital role in how information is shared online, but it also raises legal and ethical questions. These concerns focus on ownership, consent, privacy, and fairness. This section explores how indexing practices interact with law and public expectations.
Copyright, permission, and fair use
Search engines usually work on an opt-out basis, where pages are assumed indexable unless blocked. This assumption has led to legal disputes. In the Copiepresse v. Google case (2006), Belgian newspapers sued Google for showing snippets of their content without consent. The court ruled that publishing content online does not mean permission is granted to index or reuse it. It emphasized that copyright protection requires explicit authorization, not just the absence of a robots.txt file.
Following such cases, platforms like Google updated their policies to respect NoSnippet tags and made it easier to remove content from search. These updates reflected both legal requirements and ethical pressure from publishers.
Privacy and the right to be forgotten
Search engines sometimes index personal data that appears on public websites. This led to privacy regulations such as the Right to be Forgotten (RTBF) in the European Union. A 2014 ruling by the European Court of Justice allowed individuals to request the removal of outdated or irrelevant results linked to their names.
Under RTBF, the search index must be updated upon a valid request, even if the original content stays online. This rule shifts visibility by altering what can be found through search. Thousands of links have been delisted in Europe since the law came into effect.
Indexing norms, consent, and bias
Beyond legal rules, ethical indexing means respecting webmaster intent. Standards like the Robots Exclusion Protocol and the noindex meta tag serve as common tools to signal which content should stay out of search. Though these are not enforceable laws, most major search engines follow them closely.
When ignored, these norms can lead to conflict—especially with web scrapers or operators who index private or sensitive content. Ethical practice includes removing mistakenly published pages or respecting deletion requests, even when not legally bound to do so.
A further concern is bias in indexing. What gets included or excluded affects public access to knowledge. Some countries require government filtering of search results, while search engines may also exclude pages for reasons like malware, hate speech, or spam. These decisions, while sometimes necessary, place significant editorial power in the hands of index providers.
Ongoing legal balance
While web indexing enables broad access to digital information, it must also respect content ownership, privacy rights, and public interest. Courts, regulators, and platform policies continue to shape how indexing should function. The field evolves as new expectations emerge, seeking balance between open information and fair control.
References
- https://en.wikipedia.org/wiki/Search_engine_indexing
- https://en.wikipedia.org/wiki/Web_indexing
- https://audits.com/seo/insights/history-of-search-engines/
- https://www.websearchworkshop.co.uk/altavista_history.php
- https://zyppy.com/seo/google-index-size/
- https://en.wikipedia.org/wiki/CiteSeerX
- https://www.webdesignmuseum.org/web-design-history/robots-txt-1994
- https://www.onely.com/blog/ultimate-guide-to-indexing-seo/
- https://en.wikipedia.org/wiki/Wikipedia:Controlling_search_engine_indexing
- https://www.lexology.com/library/detail.aspx?g=befe6258-9709-4eb8-9557-d9ee0e99cff5
- https://www.theguardian.com/technology/2014/may/15/hundreds-google-wipe-details-search-index-right-forgotten
- Fallow Us on:
